Causal Survival Analysis#
The modules under causallib.estimation estimate treatment effect on outcomes that are measured at a particular time point (e.g., effect of smoking cessation on weight gain measured in 1982, or a binary outcome indicating occurrence of event within a specified observation period). Often, however, we are concerned with estimating treatment effect on the expected time until the occurrence of an event. This is called survival analysis, and when coupled with confounders adjustment, it is causal survival analysis. Modules for causal survival analysis can be found under causallib.survival.
This example notebook uses the NHEFS (National Health Epidemiologic Followup Study) data. It includes 1629 cigarette smokers who were aged 25-74 years at baseline and who were alive through the year 1982. All 1629 individuals were then followed for a period of 10 years, in which 318 of them died before the end of 1992, so the survival time of the remaining 1311 individuals is aministratively censored at 10 years. “Treatment assignment” was smoking cessation status, with A=1 indicating quitters and A=0 indicatong non-quitters.
We follow the analyses suggested by Hernán and Robins in their Causal Inference book to estimate the effect of smoking cessation on death.
Data#
We start by loading the dataset (with some pre-processing, e.g. column selection and creation of square features/dummy varialbes).
In addition to the standard causallib inputs of X - baseline covariates, a - treatment assignment and y - outcome indicator,
a new variable t is introduced, measuring time from the beginning of observation period to an occurrence of event.
An event may be right-censoring (where y=0) or an outcome of interest, or “death” (where y=1, which is also a type of censoring).
from causallib.datasets.data_loader import load_nhefs_survival
# Load and pre-process NHEFS data
data = load_nhefs_survival()
X, a, t, y = data.X, data.a, data.t, data.y
print(f"X shape = {X.shape}")
X.join(a).join(t).join(y)
X shape = (1629, 18)
| sex | race | age | smokeintensity | smokeyrs | wt71 | age^2 | wt71^2 | smokeintensity^2 | smokeyrs^2 | active_1 | active_2 | education_2 | education_3 | education_4 | education_5 | exercise_1 | exercise_2 | qsmk | longevity | death | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 1 | 42 | 30 | 29 | 79.04 | 1764 | 6247.3216 | 900 | 841 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 121.0 | 0 |
| 1 | 0 | 0 | 36 | 20 | 24 | 58.63 | 1296 | 3437.4769 | 400 | 576 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 121.0 | 0 |
| 2 | 1 | 1 | 56 | 20 | 26 | 56.81 | 3136 | 3227.3761 | 400 | 676 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 121.0 | 0 |
| 3 | 0 | 1 | 68 | 3 | 53 | 59.42 | 4624 | 3530.7364 | 9 | 2809 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 26.0 | 1 |
| 4 | 0 | 0 | 40 | 20 | 19 | 87.09 | 1600 | 7584.6681 | 400 | 361 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 121.0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1624 | 0 | 0 | 45 | 40 | 29 | 63.05 | 2025 | 3975.3025 | 1600 | 841 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 121.0 | 0 |
| 1625 | 1 | 0 | 47 | 20 | 31 | 57.72 | 2209 | 3331.5984 | 400 | 961 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 121.0 | 0 |
| 1626 | 1 | 0 | 51 | 40 | 30 | 62.71 | 2601 | 3932.5441 | 1600 | 900 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 121.0 | 0 |
| 1627 | 0 | 0 | 68 | 15 | 46 | 52.39 | 4624 | 2744.7121 | 225 | 2116 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 121.0 | 0 |
| 1628 | 0 | 0 | 29 | 30 | 14 | 90.83 | 841 | 8250.0889 | 900 | 196 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 121.0 | 0 |
1629 rows × 21 columns
import pandas as pd
pd.crosstab(a, y, margins=True)
| death | 0 | 1 | All |
|---|---|---|---|
| qsmk | |||
| 0 | 985 | 216 | 1201 |
| 1 | 326 | 102 | 428 |
| All | 1311 | 318 | 1629 |
We see that 26.3% (428/1629) of individuals quit smoking, out of which 76.17% (326/428) survived at 10 years. In contrast, 82% (985/1201) of the NON-quitters survived. This is a surprising result, knowing the well-established health hazards of smoking. Of course, the quitters and non-quitters are not exchangable, meaning that treatment assignment is correlated with baseline covariates, such as age:
pd.DataFrame([X.age, a]).T.groupby("qsmk").agg({"age": "mean"}) # qsmk = quit smoking indicator
| age | |
|---|---|
| qsmk | |
| 0 | 42.924230 |
| 1 | 46.696262 |
Mean age was 46.7 for quitters and 43 for non-quitters, which might explain (at least some) of the excess mortality in the quitters group. We’ll start by plotting unadjusted Kaplan-Meier curves, using the popular lifelines survival analysis Python package.
%matplotlib inline
import lifelines
import matplotlib.pyplot as plt
plt.rcParams["figure.figsize"] = [12, 10]
fig = plt.figure()
ax = plt.axes()
kmf = lifelines.KaplanMeierFitter()
kmf.fit(durations=t[a == 0], event_observed=y[a == 0], label="non-quitters")
kmf.plot_survival_function(ax=ax)
kmf.fit(durations=t[a == 1], event_observed=y[a == 1], label="quitters")
kmf.plot_survival_function(ax=ax)
plt.title("Unadjusted survival of smoke quitters vs. non-quitters in a 10 years observation period")
plt.show()
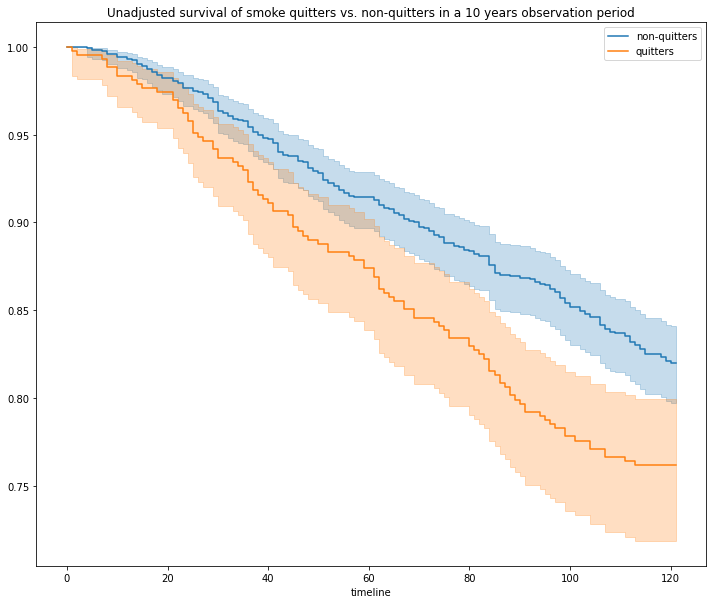
Unadjusted curves may also be computed with a built-in implementation using causallib.survival.MarginalSurvival (e.g., if lifelines is not installed)
def plot_survival_curves(curves, labels, title):
survival_0 = round(100.0 * curves[0].values[-1], 2)
survival_1 = round(100.0 * curves[1].values[-1], 2)
diff = round(survival_1 - survival_0, 2)
text = f"Survival at 10 years, {labels[1]} : {survival_1}%, {labels[0]} : {survival_0}%, diff: {diff}%"
fig = plt.figure()
ax = plt.axes()
ax.plot(curves[0], label=labels[0])
ax.plot(curves[1], label=labels[1])
ax.grid()
plt.legend()
plt.title(title)
plt.text(0, -0.1, text, transform=ax.transAxes, fontsize=14)
plt.show()
from causallib.survival.marginal_survival import MarginalSurvival
marginal_survival = MarginalSurvival()
marginal_survival.fit(X, a, t, y)
population_averaged_survival_curves = marginal_survival.estimate_population_outcome(X, a, t, y)
plot_survival_curves(
population_averaged_survival_curves,
labels=["non-quitters", "quitters"],
title="Unadjusted survival of smoke quitters vs. non-quitters in a 10 years observation period",
)
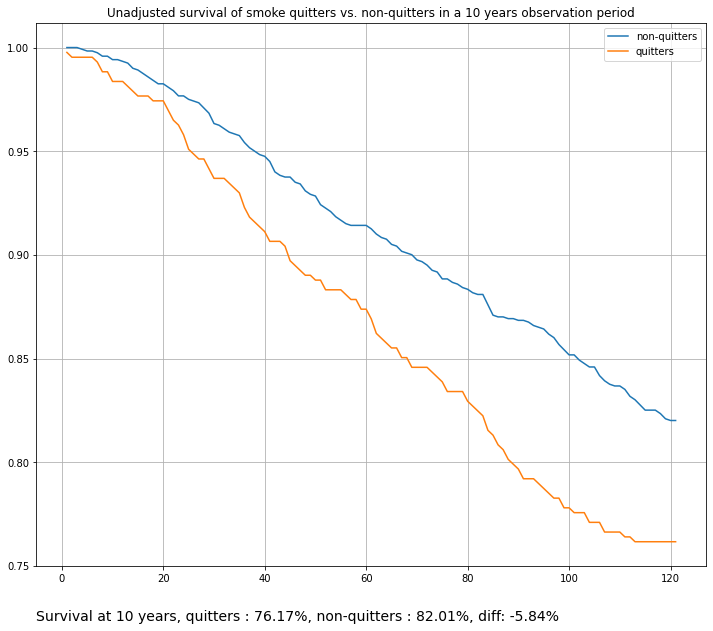
Accounting for censoring (in this case, only death events), we still see a difference in survival at 10 years, in favor of cigarette smokers. A surprising result.
WeightedSurvival#
See section 17.4 (“IP weighting of marginal structural models”) of the Causal Inference book.
We can adjust for confounders by using causallib’s WeightEstimator (such as IPW) to generate a weighted pseudo-population, in which the quitters and non-quitters are exchangable. Then, we can compute survival curves on this weighted population to get an un-confounded effect.
import warnings
from sklearn.exceptions import ConvergenceWarning
from sklearn.linear_model import LogisticRegression
from causallib.estimation import IPW
from causallib.evaluation import evaluate
warnings.simplefilter(action="ignore", category=FutureWarning)
warnings.simplefilter(action="ignore", category=ConvergenceWarning)
# Fit an inverse propensity model
ipw = IPW(learner=LogisticRegression(max_iter=800))
ipw.fit(X, a)
# Evaluate
evaluation_results = evaluate(ipw, X, a, y, metrics_to_evaluate={})
f, ax = plt.subplots(figsize=(8, 8))
evaluation_results.plot_covariate_balance(kind="love", ax=ax, phase="train");
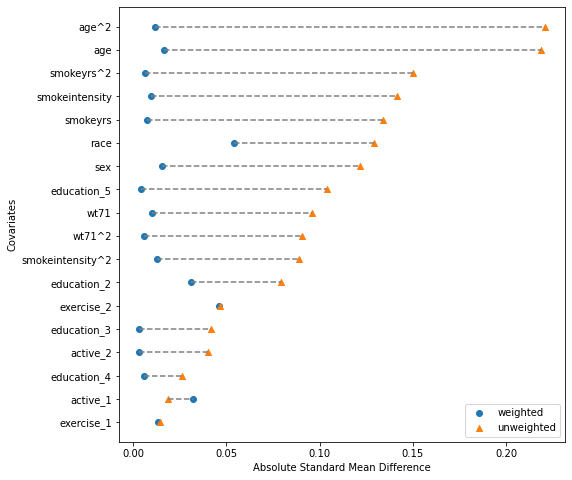
We now have an IPW module that achieves good feature balancing (SMD < 0.1 for all features after weighting).
Let’s combine IPW with survival analysis, using the causalib.survival.WeightedSurvival module.
from causallib.survival.weighted_survival import WeightedSurvival
# Compute adjusted survival curves
weighted_survival = WeightedSurvival(weight_model=ipw)
weighted_survival.fit(
X, a
) # fit weight model (we can actually skip this since it was already fitted above)
population_averaged_survival_curves = weighted_survival.estimate_population_outcome(X, a, t, y)
plot_survival_curves(
population_averaged_survival_curves,
labels=["non-quitters", "quitters"],
title="IPW-adjusted survival of smoke quitters vs. non-quitters in a 10 years observation period",
)
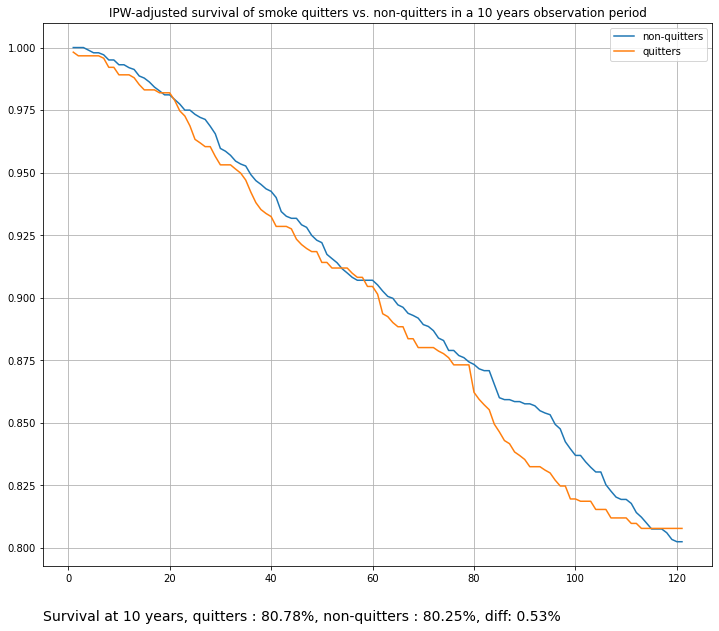
The difference in survival at 10 years diminishes after adjustments (probably to the point of being insignificant. Can be determined by bootstrap sampling, for example).
These curves were generated with an internal, non-parametric default Kaplan-Meier estimator. They can be further smoothed by using a parametric hazards model instead. Note that a weighted hazards model is conditioned on time only, e.g., it does not take covariates into account (unlike Standardization, see below).
# Compute adjusted survival curves with a parametric hazards model
weighted_survival = WeightedSurvival(
weight_model=ipw, survival_model=LogisticRegression()
) # note the survival_model param (use a parametric hazards model)
weighted_survival.fit(X, a)
population_averaged_survival_curves = weighted_survival.estimate_population_outcome(X, a, t, y)
plot_survival_curves(
population_averaged_survival_curves,
labels=["non-quitters", "quitters"],
title="IPW-adjusted survival of smoke quitters vs. non-quitters in a 10 years observation period, parametric curves",
)
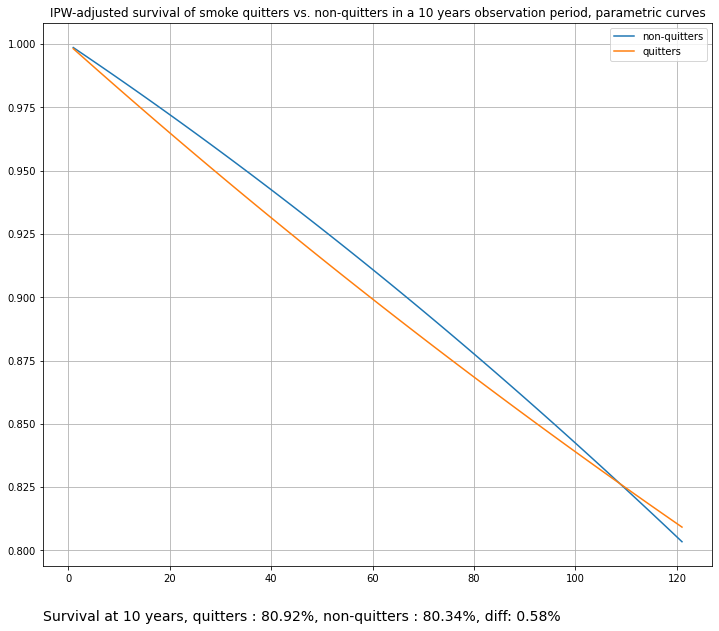
These curves may be TOO smooth, as they were modeled with a linear hazards model. We can use a more expressive alternative with some feature engineering:
# Compute adjusted survival curves with a parametric hazards model and feature engineering
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
# Init sklearn pipeline with feature transformation and logistic regression
pipeline = Pipeline(
[("transform", PolynomialFeatures(degree=2)), ("LR", LogisticRegression(max_iter=1000))]
)
weighted_survival = WeightedSurvival(
weight_model=ipw, survival_model=pipeline
) # note the survival_model param (use a parametric hazards model)
weighted_survival.fit(X, a)
population_averaged_survival_curves = weighted_survival.estimate_population_outcome(X, a, t, y)
plot_survival_curves(
population_averaged_survival_curves,
labels=["non-quitters", "quitters"],
title="IPW-adjusted survival of smoke quitters vs. non-quitters in a 10 years observation period, parametric curves ver. 2",
)
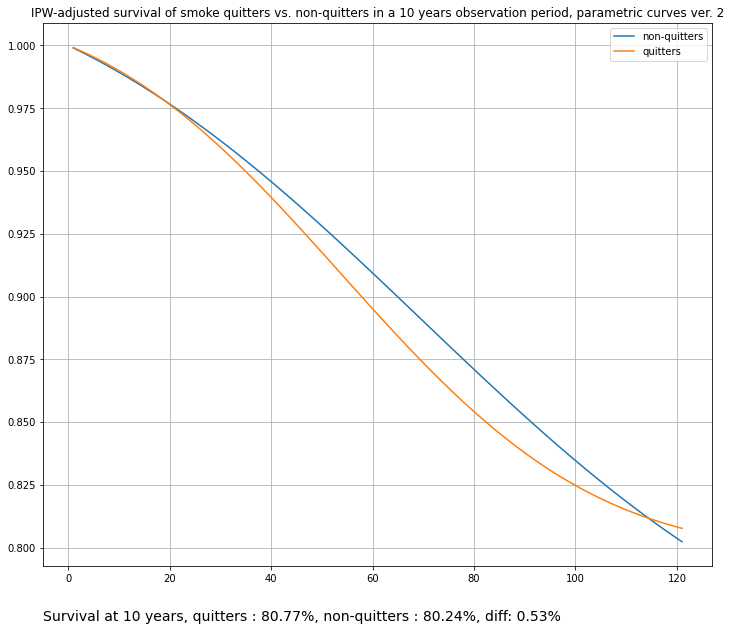
Alternatively, we can plug-in any UnivariateFitter from the lifelines package, such as PiecewiseExponentialFitter or WeibullFitter:
# Compute adjusted survival curves with a lifelines PieacewiseExponentialFitter
weighted_survival = WeightedSurvival(
weight_model=ipw,
survival_model=lifelines.PiecewiseExponentialFitter(breakpoints=range(1, 120, 30)),
)
weighted_survival.fit(X, a)
population_averaged_survival_curves = weighted_survival.estimate_population_outcome(X, a, t, y)
plot_survival_curves(
population_averaged_survival_curves,
labels=["non-quitters", "quitters"],
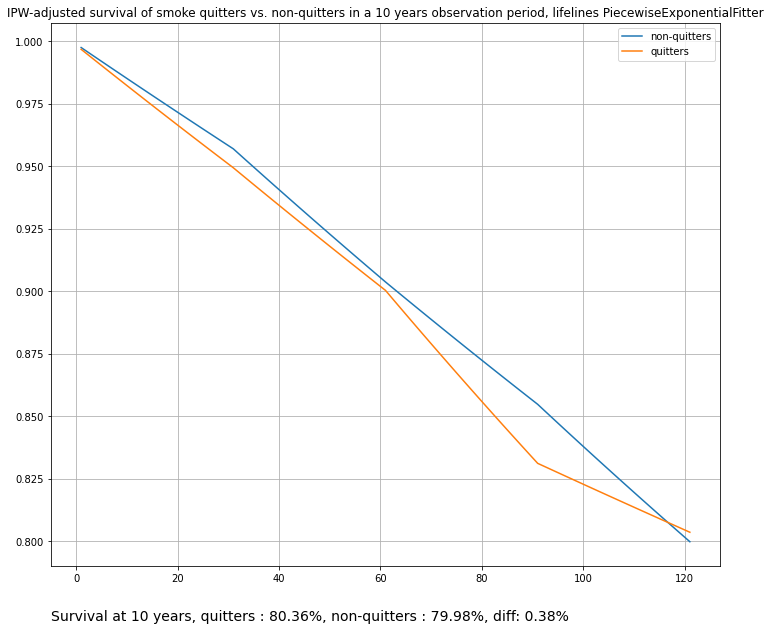
title="IPW-adjusted survival of smoke quitters vs. non-quitters in a 10 years observation period, lifelines PiecewiseExponentialFitter",
)
# Compute adjusted survival curves with a lifelines WeibullFitter
weighted_survival = WeightedSurvival(weight_model=ipw, survival_model=lifelines.WeibullFitter())
weighted_survival.fit(X, a)
population_averaged_survival_curves = weighted_survival.estimate_population_outcome(X, a, t, y)
plot_survival_curves(
population_averaged_survival_curves,
labels=["non-quitters", "quitters"],
title="IPW-adjusted survival of smoke quitters vs. non-quitters in a 10 years observation period, lifelines WeibullFitter",
)
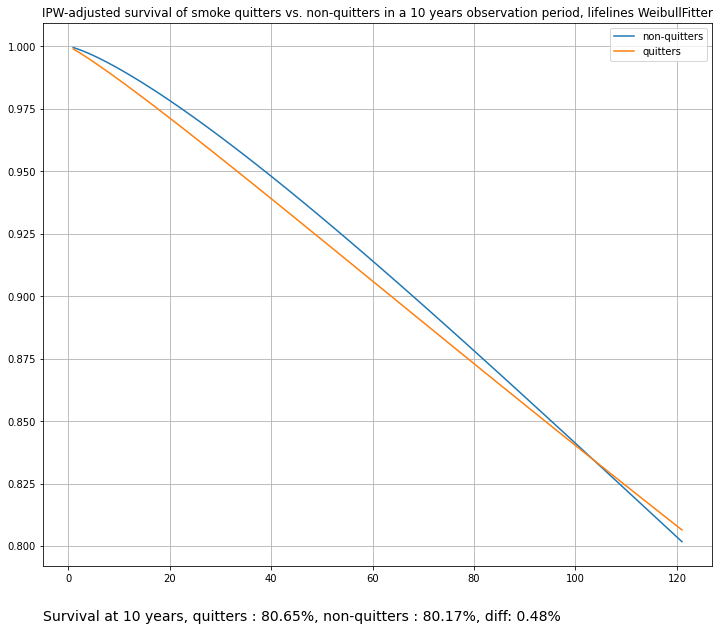
StandardizedSurvival#
See section 17.5 (“The parametric g-formula”) of the Causal Inference book.
In parametric standardization, also known as the “parametric g-formula”, survival at time step k is a weighted average of the conditional survivals within levels of covariates X and treatment assignment a, with the proportion of individuals in each stratum as the weights. In other words, similarly to a standardization with a simple outcome model (S-Learner), we fit a hazards model that also includes baseline covariates. This hazards model is then used to compute survival curves.
from causallib.survival.standardized_survival import StandardizedSurvival
standardized_survival = StandardizedSurvival(survival_model=LogisticRegression(max_iter=4000))
standardized_survival.fit(X, a, t, y)
population_averaged_survival_curves = standardized_survival.estimate_population_outcome(X, a, t)
plot_survival_curves(
population_averaged_survival_curves,
labels=["non-quitters", "quitters"],
title="Standardized survival of smoke quitters vs. non-quitters in a 10 years observation period",
)
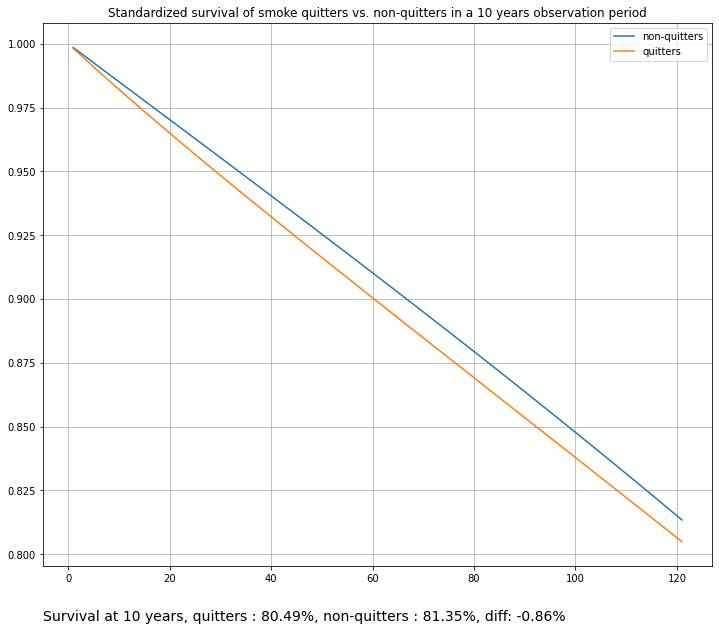
Or instead of plugging in an skelarn estimator, we can use a RegressionFitter from the lifelines package, such as the Cox Proportional Hazards Fitter:
# Use lifelines Cox Proportional Hazards Fitter as a survival model for standardization
standardized_survival_cox = StandardizedSurvival(survival_model=lifelines.CoxPHFitter())
standardized_survival_cox.fit(X, a, t, y)
population_averaged_survival_curves = standardized_survival_cox.estimate_population_outcome(X, a, t)
plot_survival_curves(
population_averaged_survival_curves,
labels=["non-quitters", "quitters"],
title="Standardized survival of smoke quitters vs. non-quitters in a 10 years observation period (Cox PH)",
)
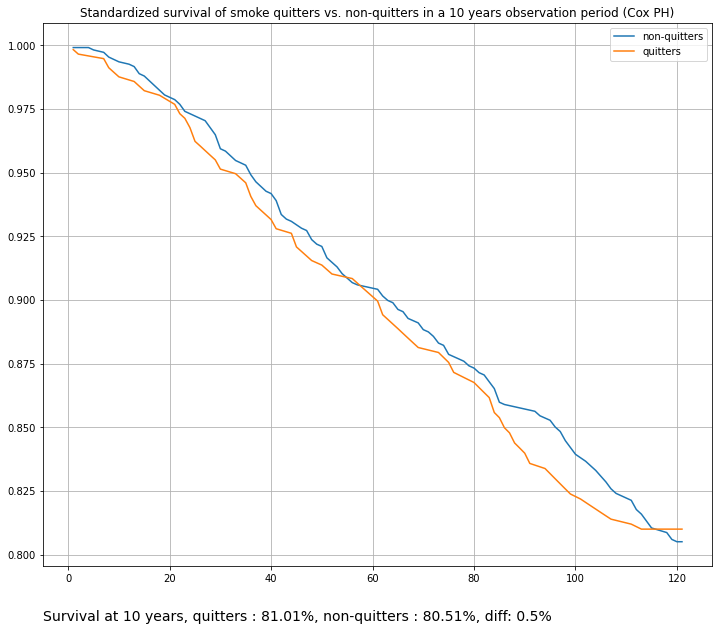
Since in Standardization we model point hazard conditioned on both covariates and time, it is important to have a well specified model. Using a too simple linear model might result in “rigid”, overly simplified survival curves. Here we add additional time features with the help of a custom scikit-learn transformer to yield smoother curves. Compare with the first plot on the StandardizedSurvival section above (cell 13).
import numpy as np
from sklearn.base import BaseEstimator, TransformerMixin
class TimeTransform(BaseEstimator, TransformerMixin):
"""
Simple transformer for adding time points transformations
"""
def __init__(self, time_col_name):
super().__init__()
self.time_col_name = time_col_name
def fit(self, X, y=None):
return self
def transform(self, X, y=None):
X_ = X.copy()
X_[self.time_col_name + "^2"] = X_[self.time_col_name] ** 2
X_[self.time_col_name + "^3"] = X_[self.time_col_name] ** 3
X_[self.time_col_name + "_sqrt"] = np.sqrt(X_[self.time_col_name])
return X_
time_transform_pipeline = Pipeline(
[("transform", TimeTransform(time_col_name=t.name)), ("LR", LogisticRegression(max_iter=2000))]
)
standardized_survival = StandardizedSurvival(survival_model=time_transform_pipeline)
standardized_survival.fit(X, a, t, y)
population_averaged_survival_curves = standardized_survival.estimate_population_outcome(X, a, t)
plot_survival_curves(
population_averaged_survival_curves,
labels=["non-quitters", "quitters"],
title="Standardized survival of smoke quitters vs. non-quitters in a 10 years observation period",
)
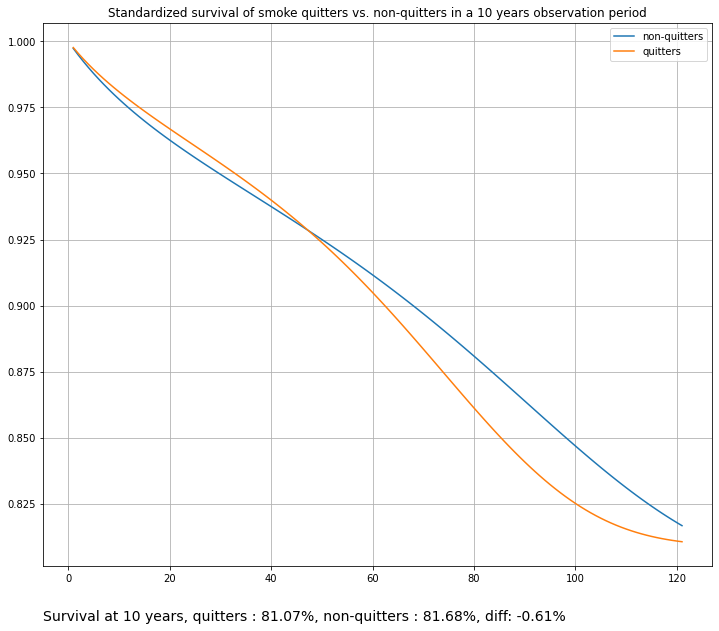
Weighted Standardized Survival#
We may also combine weighting with standardization, using the WeightedStandardizedSurvival module. Here we combine an inverse propensity weighting model (to re-weight population based on their baseline covariates) and then run a weighted regression with a Standardization model:
from causallib.survival.weighted_standardized_survival import WeightedStandardizedSurvival
ipw = IPW(learner=LogisticRegression(max_iter=2000))
poly_transform_pipeline = Pipeline(
[("transform", PolynomialFeatures(degree=2)), ("LR", LogisticRegression(max_iter=8000, C=1.5))]
)
weighted_standardized_survival = WeightedStandardizedSurvival(
survival_model=poly_transform_pipeline, weight_model=ipw
)
weighted_standardized_survival.fit(X, a, t, y)
population_averaged_survival_curves = weighted_standardized_survival.estimate_population_outcome(
X, a, t
)
plot_survival_curves(
population_averaged_survival_curves,
labels=["non-quitters", "quitters"],
title="Weighted standardized survival of smoke quitters vs. non-quitters in a 10 years observation period",
)
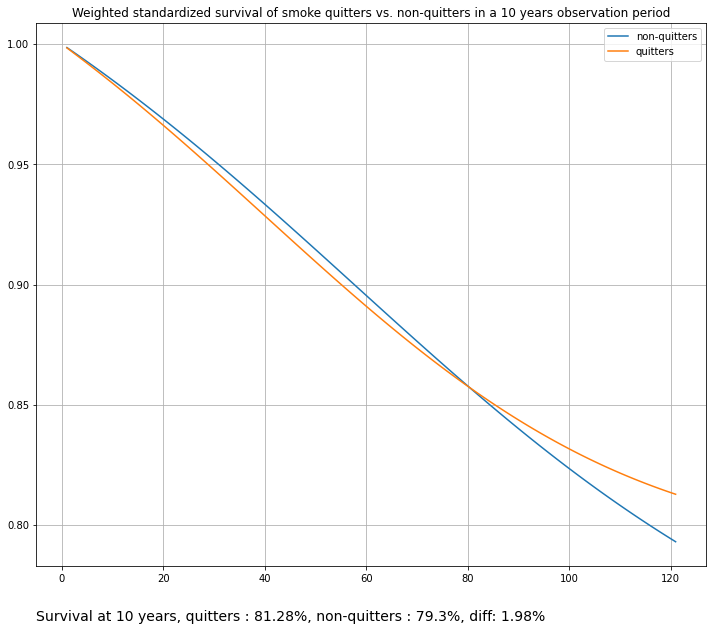
Or instead of plugging in an skelarn estimator, we can use a RegressionFitter from the lifelines package, such as the Cox Proportional Hazards Fitter. This is a weighted Cox analysis.
ipw = IPW(learner=LogisticRegression(max_iter=1000))
weighted_standardized_survival = WeightedStandardizedSurvival(survival_model=lifelines.CoxPHFitter(), weight_model=ipw)
# Note the fit_kwargs (passed to CoxPHFitter.fit() method)
weighted_standardized_survival.fit(X, a, t, y, fit_kwargs={'robust': True})
# Without setting 'robust=True', we'll get the following warning:
"""StatisticalWarning: It appears your weights are not integers, possibly propensity or sampling scores then?
It's important to know that the naive variance estimates of the coefficients are biased. Instead a) set `robust=True` in the call to `fit`, or b) use Monte Carlo to
estimate the variances."""
population_averaged_survival_curves = weighted_standardized_survival.estimate_population_outcome(X, a, t)
plot_survival_curves(population_averaged_survival_curves,
labels=['non-quitters', 'quitters'],
title='Weighted standardized survival of smoke quitters vs. non-quitters in a 10 years observation period')
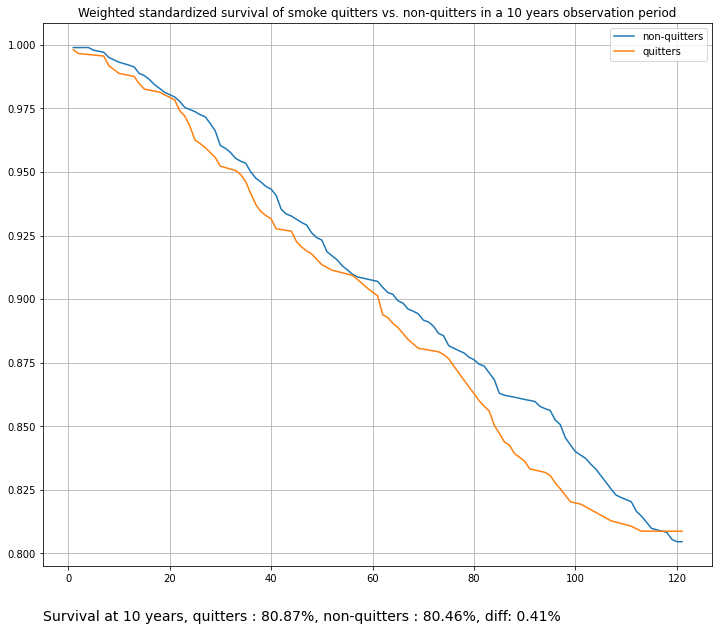
Summary#
Side by side comparison of multiple models.
import itertools
def plot_multiple_models(models_dict):
grid_dims = (int(np.round(np.sqrt(len(models_dict)))), int(np.ceil(np.sqrt(len(models_dict)))))
grid_indices = itertools.product(range(grid_dims[0]), range(grid_dims[1]))
fig, ax = plt.subplots(*grid_dims)
models_names = list(models_dict.keys())
for model_name, plot_idx in zip(models_names, grid_indices):
model = models_dict[model_name]
model.fit(X, a, t, y)
curves = model.estimate_population_outcome(X, a, t, y)
ax[plot_idx].plot(curves[0])
ax[plot_idx].plot(curves[1])
ax[plot_idx].set_title(model_name)
ax[plot_idx].set_ylim(0.7, 1.02)
ax[plot_idx].grid()
plt.tight_layout()
plt.show()
MODELS_DICT = {
"MarginalSurvival Kaplan-Meier": MarginalSurvival(survival_model=None),
"MarginalSurvival LogisticRegression": MarginalSurvival(
survival_model=LogisticRegression(max_iter=2000)
),
"MarginalSurvival PiecewiseExponential": MarginalSurvival(
survival_model=lifelines.PiecewiseExponentialFitter(breakpoints=range(1, 120, 10))
),
"WeightedSurvival Kaplan-Meier": WeightedSurvival(
weight_model=IPW(LogisticRegression(max_iter=2000)), survival_model=None
),
"WeightedSurvival LogisticRegression": WeightedSurvival(
weight_model=IPW(LogisticRegression(max_iter=2000)),
survival_model=LogisticRegression(max_iter=2000),
),
"WeightedSurvival WeibullFitter": WeightedSurvival(
weight_model=IPW(LogisticRegression(max_iter=2000)),
survival_model=lifelines.WeibullFitter(),
),
"StandardizedSurvival LogisticRegression": StandardizedSurvival(
survival_model=LogisticRegression(max_iter=2000)
),
"StandardizedSurvival Cox": StandardizedSurvival(survival_model=lifelines.CoxPHFitter()),
"WeightedStandardizedSurvival": WeightedStandardizedSurvival(
weight_model=IPW(LogisticRegression(max_iter=2000)),
survival_model=LogisticRegression(max_iter=2000),
),
}
plot_multiple_models(MODELS_DICT)
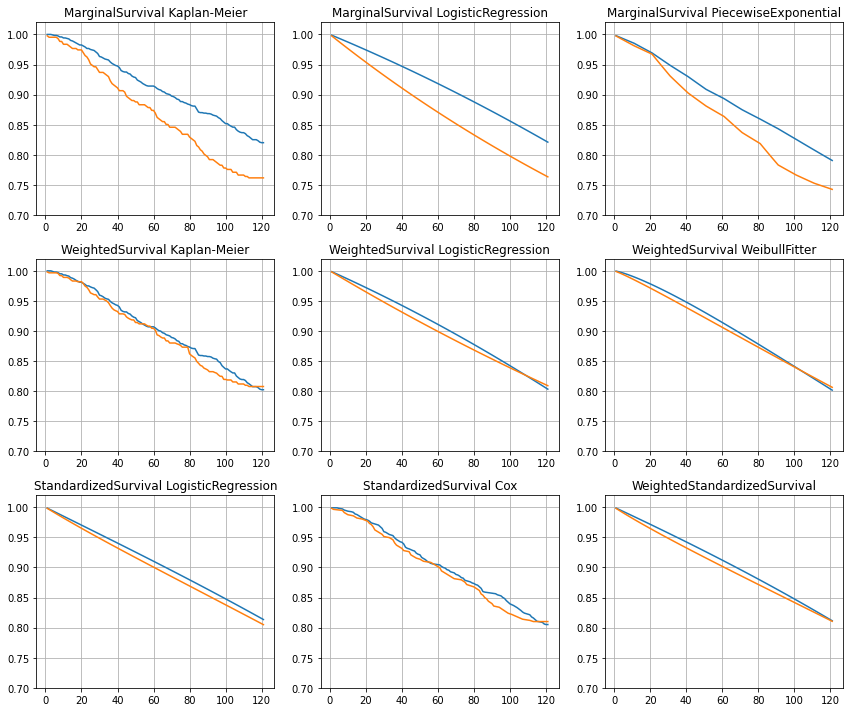
Individual-level survival curves#
When using direct-outcome models (StandardizedSurvival and WightedStnadardizedSurvival) in causallib,
it is possible to generate individual-level effect estimation and survival curves.
%matplotlib inline
import matplotlib as mpl
import seaborn.objects as so
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import make_pipeline
from causallib.survival import StandardizedSurvival
from causallib.datasets import load_nhefs_survival
data = load_nhefs_survival(augment=False, onehot=False)
data.t = data.t.rename("longevity")
data.X.join(data.a).join(data.t).join(data.y)
| active | age | education | exercise | race | sex | smokeintensity | smokeyrs | wt71 | qsmk | longevity | death | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 42 | 1 | 2 | 1 | 0 | 30 | 29 | 79.04 | 0 | 120.0 | 0 |
| 1 | 0 | 36 | 2 | 0 | 0 | 0 | 20 | 24 | 58.63 | 0 | 120.0 | 0 |
| 2 | 0 | 56 | 2 | 2 | 1 | 1 | 20 | 26 | 56.81 | 0 | 120.0 | 0 |
| 3 | 1 | 68 | 1 | 2 | 1 | 0 | 3 | 53 | 59.42 | 0 | 26.0 | 1 |
| 4 | 1 | 40 | 2 | 1 | 0 | 0 | 20 | 19 | 87.09 | 0 | 120.0 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1624 | 0 | 45 | 1 | 0 | 0 | 0 | 40 | 29 | 63.05 | 0 | 120.0 | 0 |
| 1625 | 0 | 47 | 1 | 0 | 0 | 1 | 20 | 31 | 57.72 | 0 | 120.0 | 0 |
| 1626 | 0 | 51 | 3 | 0 | 0 | 1 | 40 | 30 | 62.71 | 0 | 120.0 | 0 |
| 1627 | 1 | 68 | 1 | 1 | 0 | 0 | 15 | 46 | 52.39 | 0 | 120.0 | 0 |
| 1628 | 1 | 29 | 2 | 1 | 0 | 0 | 30 | 14 | 90.83 | 1 | 120.0 | 0 |
1629 rows × 12 columns
Now let’s create a formula-based data-transformer that will allow to easily specify two things:
Flexibly model continuous variables using splines, and
Create treatment interaction with all variables to allow for effect modification.
from formulaic import Formula
from sklearn.base import BaseEstimator, TransformerMixin
class FormulaTransformer(BaseEstimator, TransformerMixin):
def __init__(self, formula):
super().__init__()
self.formula = formula
def fit(self, X, y=None):
return self
def transform(self, X, y=None):
X_ = Formula(self.formula).get_model_matrix(X)
return X_
formula = f"""
~ 1
+ {data.a.name}*(
C(exercise) + C(active) + C(education)
+ sex + race + bs(age, degree=5)
+ bs(smokeintensity) + bs(smokeyrs)
+ bs(wt71)
+ bs({data.t.name}, degree=5)
)
"""
estimator = make_pipeline(
FormulaTransformer(formula),
LogisticRegression(penalty="none", max_iter=1000)
)
model = StandardizedSurvival(
estimator,
stratify=False,
)
model.fit(data.X, data.a, data.t, data.y)
po = model.estimate_individual_outcome(data.X, data.a, data.t)
po
| qsmk | 0 | ... | 1 | ||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| subject_id | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 1619 | 1620 | 1621 | 1622 | 1623 | 1624 | 1625 | 1626 | 1627 | 1628 |
| t | |||||||||||||||||||||
| 1 | 0.999805 | 0.999935 | 0.999794 | 0.997956 | 0.999938 | 0.999945 | 0.999820 | 0.999981 | 0.999710 | 0.999888 | ... | 0.996362 | 0.999992 | 0.998758 | 0.999730 | 0.999881 | 0.999698 | 0.999790 | 0.999802 | 0.994712 | 0.999980 |
| 2 | 0.999574 | 0.999858 | 0.999549 | 0.995534 | 0.999864 | 0.999880 | 0.999606 | 0.999958 | 0.999365 | 0.999756 | ... | 0.992385 | 0.999982 | 0.997397 | 0.999434 | 0.999750 | 0.999367 | 0.999560 | 0.999585 | 0.988940 | 0.999958 |
| 3 | 0.999302 | 0.999767 | 0.999261 | 0.992689 | 0.999777 | 0.999803 | 0.999354 | 0.999931 | 0.998960 | 0.999599 | ... | 0.988046 | 0.999972 | 0.995907 | 0.999109 | 0.999607 | 0.999004 | 0.999308 | 0.999347 | 0.982657 | 0.999933 |
| 4 | 0.998984 | 0.999661 | 0.998924 | 0.989376 | 0.999676 | 0.999713 | 0.999059 | 0.999900 | 0.998486 | 0.999417 | ... | 0.983327 | 0.999961 | 0.994282 | 0.998755 | 0.999450 | 0.998608 | 0.999032 | 0.999087 | 0.975837 | 0.999907 |
| 5 | 0.998615 | 0.999537 | 0.998534 | 0.985550 | 0.999558 | 0.999609 | 0.998718 | 0.999863 | 0.997937 | 0.999205 | ... | 0.978207 | 0.999950 | 0.992513 | 0.998369 | 0.999279 | 0.998176 | 0.998731 | 0.998803 | 0.968457 | 0.999878 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 116 | 0.785440 | 0.922480 | 0.774365 | 0.081086 | 0.925822 | 0.934129 | 0.799709 | 0.976451 | 0.697937 | 0.870544 | ... | 0.128062 | 0.995263 | 0.494223 | 0.857744 | 0.934465 | 0.842329 | 0.887524 | 0.893539 | 0.050856 | 0.988552 |
| 117 | 0.783138 | 0.921576 | 0.771963 | 0.078655 | 0.924955 | 0.933355 | 0.797540 | 0.976168 | 0.694893 | 0.869079 | ... | 0.127808 | 0.995258 | 0.493890 | 0.857618 | 0.934404 | 0.842191 | 0.887423 | 0.893443 | 0.050710 | 0.988542 |
| 118 | 0.780898 | 0.920694 | 0.769625 | 0.076352 | 0.924109 | 0.932601 | 0.795429 | 0.975892 | 0.691936 | 0.867651 | ... | 0.127625 | 0.995255 | 0.493648 | 0.857527 | 0.934360 | 0.842091 | 0.887350 | 0.893374 | 0.050604 | 0.988534 |
| 119 | 0.778728 | 0.919838 | 0.767360 | 0.074177 | 0.923289 | 0.931869 | 0.793382 | 0.975624 | 0.689075 | 0.866266 | ... | 0.127495 | 0.995253 | 0.493478 | 0.857463 | 0.934330 | 0.842020 | 0.887298 | 0.893325 | 0.050529 | 0.988528 |
| 120 | 0.776634 | 0.919011 | 0.765175 | 0.072132 | 0.922496 | 0.931161 | 0.791407 | 0.975365 | 0.686317 | 0.864927 | ... | 0.127406 | 0.995251 | 0.493360 | 0.857418 | 0.934308 | 0.841971 | 0.887262 | 0.893291 | 0.050478 | 0.988524 |
120 rows × 3258 columns
Following lifelines’ convention, the dimensions of the results place the different time-points as rows and inidividuals as columns.
The columns are further indexed by treatment assignment, as the values are potential outcomes.
This structure allows us to obtain individual-level effects (difference in survival) like we would in non-survival estimation:
effect = po[1] - po[0]
# effect
We now pivot the results, to get it into a long format which we can later plot:
effect = effect.reset_index(names="time").melt(id_vars="time", var_name="id", value_name="effect")
effect
| time | id | effect | |
|---|---|---|---|
| 0 | 1 | 0 | -0.000033 |
| 1 | 2 | 0 | -0.000051 |
| 2 | 3 | 0 | -0.000052 |
| 3 | 4 | 0 | -0.000033 |
| 4 | 5 | 0 | 0.000010 |
| ... | ... | ... | ... |
| 195475 | 116 | 1628 | 0.029716 |
| 195476 | 117 | 1628 | 0.030194 |
| 195477 | 118 | 1628 | 0.030664 |
| 195478 | 119 | 1628 | 0.031123 |
| 195479 | 120 | 1628 | 0.031568 |
195480 rows × 3 columns
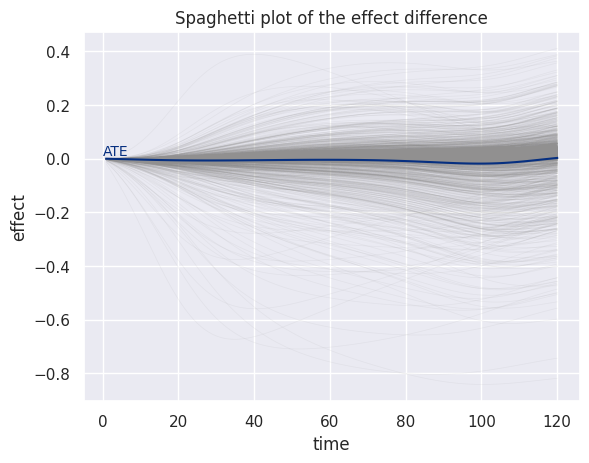
f = mpl.figure.Figure()
# Plot inidividual lines:
p = so.Plot(
effect,
x="time",
y="effect",
group="id",
).add(
so.Lines(linewidth=.5, alpha=0.1, color="#919090")
).label(
title="Spaghetti plot of the effect difference",
).on(f).plot()
# Plot average effect:
avg_effect = effect.groupby("time")["effect"].mean().reset_index()
ax = f.axes[0]
ax.plot(avg_effect["time"], avg_effect["effect"], color="#062f80")
ax.text(
0, 0, "ATE",
verticalalignment="bottom",
color="#062f80"
)
f
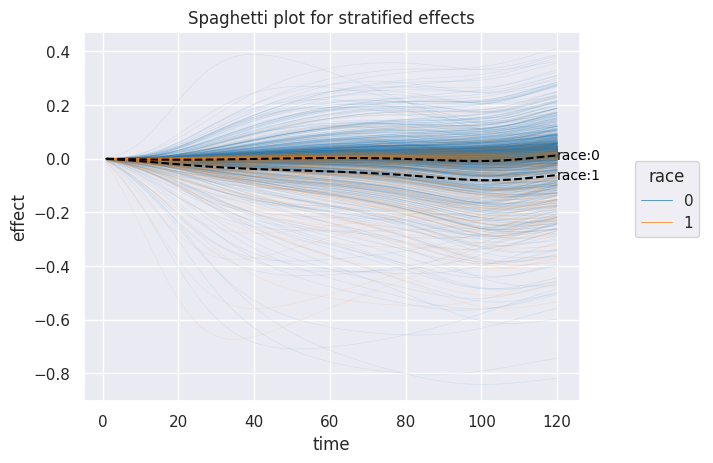
Once we have inidividual-level survival curves, we can aggregate them arbitrarily to see how the effect changes in different covariate strata
f = mpl.figure.Figure()
effectX = effect.merge(data.X, left_on="id", right_index=True)
strata = "race"
p_eff_strat = so.Plot(
effectX,
x="time",
y="effect",
color=strata, # Stratify the effect curves by
group="id",
).add(
so.Lines(linewidth=.5, alpha=0.1)
).scale(
color=so.Nominal(["#1f77b4", "#ff7f0e"]),
).label(
title="Spaghetti plot for stratified effects",
).on(f).plot()
p_eff_strat
avg_effect = effectX.groupby(["time", strata])["effect"].mean().reset_index()
ax = f.axes[0]
for s, stratum_data in avg_effect.groupby(strata):
ax.plot(
stratum_data["time"], stratum_data["effect"],
color="black", linestyle="--",
)
ax.text(
stratum_data["time"].iloc[-1], stratum_data["effect"].iloc[-1],
f"{strata}:{s}",
verticalalignment="center",
)
f